
머신러닝 기초
1. 머신러닝
: 인공지능 기반의 기술로서 컴퓨터가 데이터를 통해 스스로 학습하면서
새로운 지식을 얻어 자동으로 개선하고 결과를 예측하는 컴퓨터 알고리즘

* 규칙 기반 전문가 시스템 : if, else문으로 하드코딩된 시스템
→ 단점
- 많은 상황에 대한 규칙들을 모두 만들어 낼 수는 없음
- 제작한 로직이 특정 작업에만 국한
- 작업이 조금만 변경되더라도 전체 시스템을 다시 만들어야 할 가능성 높음
- 규칙을 설계하려면 해당 분야에 대해 잘 알고 있어야 함
그래서 머신러닝 등장 ~ !
* 머신러닝과 딥러닝의 차이
머신러닝에는 사람이 껴 있다!
그럼 사람 손 안타는 딥러닝이 더 편하고 좋은 거 아닌가요???
NO!!!!
각각 장단점이 있다!
딥러닝은 데이터가 많으면 정확도가 우수하지만
데이터가 작다면 머신러닝 알고리즘이 더 우수!
그러니 뭐가 더 좋고 나쁘고 결정할 수 없다!
2. 머신러닝 학습방법
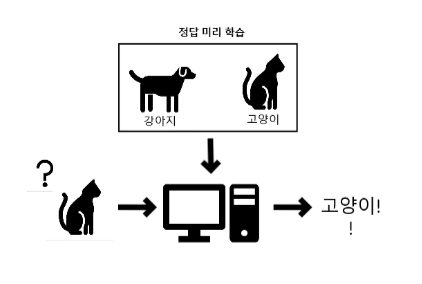
1) 지도학습
: 데이터에 대한 명시적인 답(Label)이 주어진 상태에서 컴퓨터를 학습시키는 법
대표적인 지도학습 방법으로는 분류(Classification)와 회귀(Regression)가 있다.
지도학습의 예시로는 스팸 메일 분류, 집 가격 예측의 경우를 들 수 있다.
* 분류(Classification)
- 미리 정의된 여러 클래스 레이블 중 하나를 예측하는 것
- 속성 값을 입력, 클래스 값을 출력으로 하는 모델
- 이진분류, 다중분류 등이 있음
* 회귀(Regression)
- 연속적인 숫자를 예측하는 것
- 속성값을 입력, 연속적인 실수 값을 출력으로 하는 모델
- 예측 값의 미묘한 차이가 크게 중요하지 않음
- 어떤 사람의 교육수준, 나이, 주거지를 바탕으로 연간 소득 예측 등
2) 비지도학습
: 데이터에 대한 Label(명시적인 답)이 없는 상태에서 컴퓨터를 학습시키는 방법
데이터의 숨겨진 특징, 구조, 패턴을 파악하는 데 사용
데이터를 비슷한 특성끼리 묶는 클러스터링(Clustering)과 차원축소(Dimensionality Reduction)등이 있다.
비지도학습의 예시로는 이미지 감색처리, 소비자 그룹 발견을 통한 마케팅, 손글씨 숫자 인식이 있다.

* 군집 분석(Clustering)
- 특별한 사전 가정 없이 개체들 사이의 유사성/거리에 근거하여 군집을 찾고 다음 단계의 분석을 하게 하는 방법
- 개인 또는 여러 개체를 유사한 속성을 지닌 대상들끼리 그룹핑하는 탐색적 다변량 분석 기법
- 계층적 군집 분석과 비계층적 군집분석으로 구분
* 차원축소(Dimension Reduction)
- 매우 많은 특성으로 구성된 다차원 데이터 세트의 차원을 축소해서 새로운 차원 세트를 생성
- 특성 선택과 특성 추출로 구분
- 단순하게 데이터를 압축하는 것이 아닌 차원 축소를 통해 데이터를 조금 더 잘 설명할 수 있는 요소를 추출

3) 강화학습
: 어떠한 환경에서 정의된 AI가 현재의 상태를 인식하여 선택 가능한 행동들 중
보상을 최대화 하는 행동 or 행동 순서를 선택하는 방법(게임회사에서 많이 함)
3. 머신러닝 과정 ★★★
1) Problem Identification(문제정의)
2) Data Collect(데이터 수집)
3) Data Preprocession(데이터 전처리)
4) EDA(탐색적 데이터분석)
5) Model 선택, Hyper Parameter 조정
6) Training(학습)
7) Evaluation(평가)
1) Problem Identification(문제정의)
- 비즈니스 목적 정의모델을 어떻게 사용해 이익을 얻을까?
- 현재 솔루션의 구성 파악
- 지도 vs 비지도 vs 강화
- 분류 vs 회귀
2) Data Collect(데이터 수집)
- File (CSV, XML, JSON)
- Database
- Web Crawler (뉴스, SNS, 블로그)
- IoT 센서를 통한 수집
- Survey
3) Data Preprocession(데이터 전처리)
- 결측치, 이상치 처리
- Feature Engineering (특성공학) : Scaling (단위 변환)
- Encoding (범주형 → 수치형)
- Binning (수치형 → 범주형)
- Transform (새로운 속성 추출)
4) EDA(탐색적 데이터분석)
- 기술통계, 변수간 상관관계
- 시각화 : pandas, matplotlib, seaborn
- Feature Selection (사용할 특성 선택)
5) Model 선택, Hyper Parameter 조정
- 목적에 맞는 적절한 모델 선택
- KNN, SVM, Linear Regression, Ridge, Lasso, Decision Tree, Random forest 등등
- Hyter Parameter : model의 성능을 개선하기 위해 사람이 직접 넣는 parameter - (n_neighbor=1)
6) Training(학습)
- model.fit(X_train, y_train)
- train데이터와 test데이터를 7:3 정도로 나눔
- model.predict(X_test)
7) Evaluation(평가)
| 분류 | 회귀 |
| accuracy(정확도) | MSE(Mean Squared Error) |
| recall(재현율) | RMSE(Root Mean Squared Error) |
| precision(정밀도) | |
| f1 score | R² (R Square) |

파이썬에선 scikit-learn 이라는 라이브러리를 사용할 것!
→ 회귀, 분류, 군집, 차원축소, 특성공학, 전처리, 교차검증, 파이프라인 등 머신러닝에 필요한 기능을 갖추고 있는 머신러닝 프레임워크, 라이브러리로 학습을 위한 샘플데이터도 제공하고 있음!